

این روزها هوش مصنوعی در جهان سروصدای زیادی به پا کرده است و حوزههایی که هوش مصنوعی به آنها ورود پیدا کرده بسیار گسترده گردیدهاند. مدیریت پروژه نیز از این منظر مستثنی نبوده و میتواند یکی از حوزههای جذاب برای ورود هوش مصنوعی باشد. هوش مصنوعی در مدیریت پروژه به کمک متخصصان این حوزه آمده و چندسالی است که مورد توجه جدی قرار گرفته است. مدیریت ادعا و اختلافات یکی از بخشهای پر اهمیت و جذاب است که با ورود هوش مصنوعی به آن میتواند تغییرات مثبت و چشمگیری را برای مدیریت پروژه به ارمغان بیاورد.
باوجود اینکه استفاده از هوش مصنوعی در حوزههای مختلف به اوج خود رسیده است، اما شاید برای شما نیز جالب باشد که در سال 2009 در کشور آمریکا، برای پیشبینی دعاوی صنعت ساخت با استفاده از هوش مصنوعی مدلی ارائه گردیده است. ارائه این مدل، آن هم در سال 2009 میتواند بسیاری از ادعاهایی که گفته میشود هوش مصنوعی نمیتواند کاربرد زیادی در مدیریت پروژه داشته باشد را زیر سوال ببرد. مدلی که در رابطه با آن صحبت شد، توسط Pulket و Arditi ارائه شده است ([1]). در این مقاله قصد داریم به معرفی این مدل بپردازیم.
1. مدل پیشبینی جهانی
مدیریت ادعا و اختلافات به دلیل وجود پیچیدگیهای زیاد در صنعت ساخت به یکی از موارد پر اهمیت در این صنعت تبدیل شده است. دعاوی و اختلافات درجهان هزینههای ساخت را به طور چشمگیری افزایش داده است. ازاینرو محققان و متخصصان زیادی در طول سالها به جهت کاهش این هزینهها مطالعات زیادی انجام دادهاند. در مدیریت ادعا و اختلاف برای جلوگیری از روش قضایی که بسیار پر هزینه و زمانبر است، روشهای جایگزین حل اختلاف (ADR) مانند داوری، میانجیگری و هیئتهای بررسی اختلاف بهعنوان جایگزینی برای دعاوی قضایی که معمولا طولانی و پرهزینه هستند، توسعه پیدا کردهاند. اما این تمام ماجرا نبوده و برای کاهش هزینه و زمان مدیریت دعاوی میتوان از مدلهای پیشبینی که بر پایه هوش مصنوعی هستند نیز کمک گرفت.
یکی از مدلهای ارائه شده بر پایه هوش مصنوعی، مدل پیشبینی جهانی (UPM) است. این مدل از سه فرایند اصلی به نامهای پیشپردازش (Preprocessing)، طبقهبندی (Classification) و ارزیابی (Assessment) تشکیل شده است. این مدل پیشبینی که از الگوریتمهای یادگیری ماشین (Machine Learning) و از ابزارهای پردازش داده (Data Processing Tools) بهصورت ترکیبی و برای پیشبینی نتایج استفاده مینماید، قابلتعمیم به کشورهای دیگر نیز بوده و میتواند در مقیاسهای بزرگ نیز استفاده گردد. این مدل با استفاده از ابزار WEKA ایجاد شده است. این ابزار شامل مجموعهای از الگوریتمهای یادگیری ماشین (Machine Learning) و دادهکاوی (Data Mining) است.
بر اساس چهارچوب مدل پیشبینی جهانی، بخش اول، پیشپردازش داده (Pre-Processing) بوده که شامل دو تابع ادغام داده (Data Consolidation) و انتخاب ویژگی (Attribute Selection) است که در شکل 1 نشاندادهشده است. ابتدا، مجموعهداده با استفاده از چندین الگوریتم به طور مناسب ادغام میشود (Data Consolidation). این مرحله برای اطمینان از داده موردنیاز برای یک طرح یادگیری خاص انجام میشود. در مرحله بعد، فرایند انتخاب ویژگی (Attribute Selection)، فضای زیرمجموعههای ویژگی را جستجو میکند و مرتبطترین ویژگیها را در مجموعهداده انتخاب مینماید.
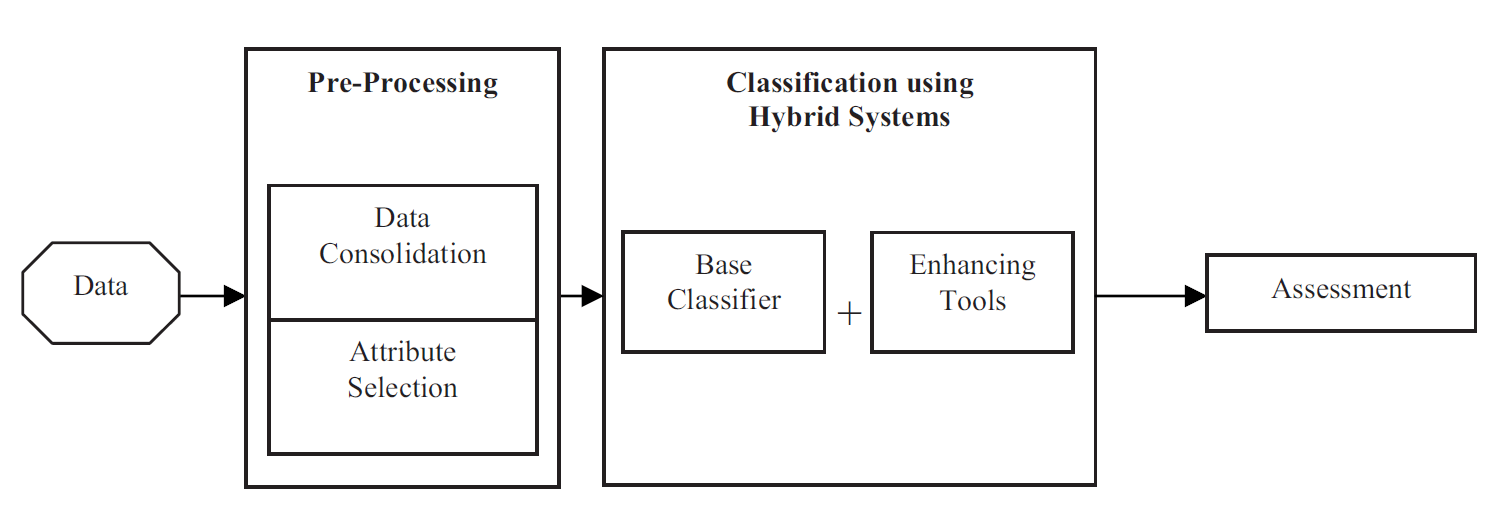
شکل 1. چهارچوب مدل پیشبینی جهانی (UPM)
در مرحله بعد، طبقهبندی بر اساس یک سیستم هیبریدی یا ترکیبی انجام میشود (Classification Using Hybrid Systems). مدل معرفی شده در این بخش، از یک طبقهبندیکننده پایه (Base Classifier) و ابزارهای بهبوددهنده (Enhancing Tools) تشکیل شده است. طبقهبندیکنندههای پایه شامل موارد زیر هستند:
- درختهای تصمیمگیری (Decision Trees)
- طرحهای یادگیری قوانین (که هر کلاس (Class) را به نوبه خود میگیرند و به دنبال راهی برای پوشش همهی نمونههای موجود در آن هستند، درعینحال نمونههایی را که در کلاس نیستند را حذف میکنند)
- طرحهای یادگیری توابع (معادلات ریاضی که به روشی طبیعی نوشته شدهاند)
اضافهشدن به یکطبقه بندیکننده پایه میتواند بهصورت برنامههای کاربردی فرا یادگیرنده (Meta Learner) یا روشهای گروهی (Ensemble Methods) صورت گیرد. همچنین در بخش ارزیابی (Assessment)، سیستمهای پیشبینی بر اساس چهار معیار عملکرد، مقایسه و ارزیابی میشوند:
- دقت پیشبینی (Prediction Accuracy)
- پایداری (Robustness)
- سرعت (Speed)
- تفسیرپذیری (Interpretability)
2. ساختار مدل پیشبینی جهانی (UPM)
برای ساختار مدل پیشبینی جهانی (UPM)، ابتدا 6 مجموعهداده شامل فایل اصلی با استفاده از روشهای تلفیق دادهها (Data Consolidation Methods) که در شکل 2 فهرست شده ایجاد میگردد. 12 روش انتخاب ویژگی با استفاده از 3 روش ارزیابی زیرمجموعه در ترکیب با 4 روش تنظیم شدند. در مجموع 72 مجموعهداده ایجاد شد که در مجموع 1152 آزمایش را ایجاد کردند (شکل 2).

شکل 2. روشهای استفاده شده در مدل پیش بینی جهانی (UPM)
بهطورکلی در این مدل از 2 مجموعهداده برای انجام آزمایش استفاده گردیده است. مجموعهداده اصلی (Original Dataset) به میزان 132 مورد و مجموعهداده افزوده شده (Augmented Dataset) به میزان 151 مورد بهکارگرفته شده و هر مجموعهداده به طور جداگانه در مدل پیشبینی جهانی وارد شدند. نتایج ایجاد شده توسط مدل پیشبینی جهانی با روش خودکار گزارش شده و در مجموع 3528 فایل خروجی نهایی برای هر یک از مجموعهدادههای اصلی و افزوده، ایجاد گردید. هر فایل حاوی نتایج دقیق آزمایشها بوده و شکلهای 3 و 4 خلاصه نتایج و دادههای آماری را برای این مجموعه داده گزارش میدهند.
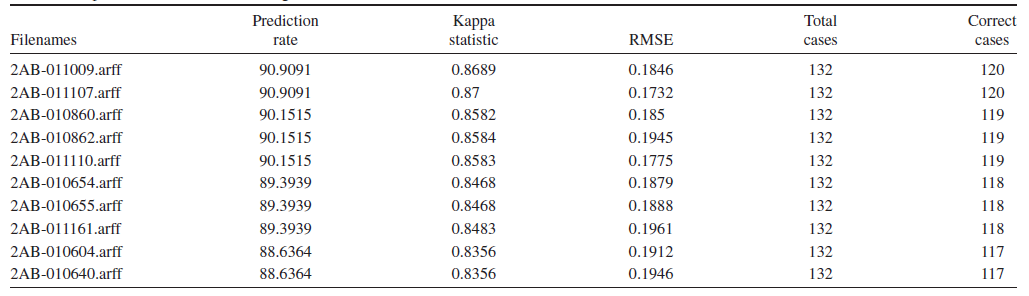
شکل 3. نتایج بدست آمده با استفاده از مجموعه داده اصلی (Original Dataset)
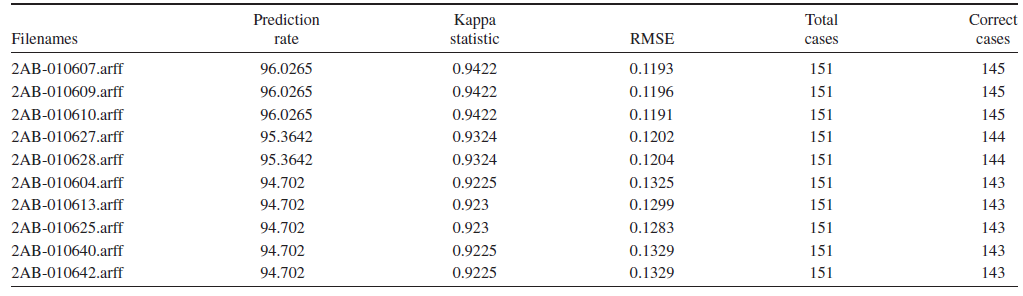
شکل 4. نتایج بدست آمده با استفاده از مجموعه داده افزودهشده (Augmented Dataset)
جمعبندی پیشبینی نتایج دعاوی قضایی پروژهها با استفاده از هوش مصنوعی (AI)
این مدل، دربرگیرنده 4 قابلیت ادغام دادهها، انتخاب بر اساس ویژگیها، طبقهبندی ترکیبی و ارزیابی عملکرد است که در سه فرآیند اصلی پردازش، طبقهبندی و ارزیابی طراحی شده است. بعد از آنکه این مدل تدوین شد، دو مجموعه داده برای تستکردن مدل در نظر گرفته میشود. این دادهها از دعاوی قضایی پروژهها که بین سالهای 1987 تا 2005 در آمریکا ثبت شده و به نتیجه ختم گردیده، انتخاب گردیدند تا نتایج مدل با نتایج واقعی دعاوی مطابقت داده شود و دقت و میزان خطای مدل برآورد گردد. نتایج بهدستآمده نشان داد که مدل ارائه شده دارای خطای بسیار کم و دقت پیشبینی بسیار بالایی است که باعث گردید بسیاری از شرکتها در آمریکا از این مدل ارائه شده برای پروژههایشان استفاده عملی نمایند. مدلی که در مقایسه با مدل پیشبینی سنتی (Traditional Prediction Model) بسیار کارآمدتر عمل مینماید (شکل 5).
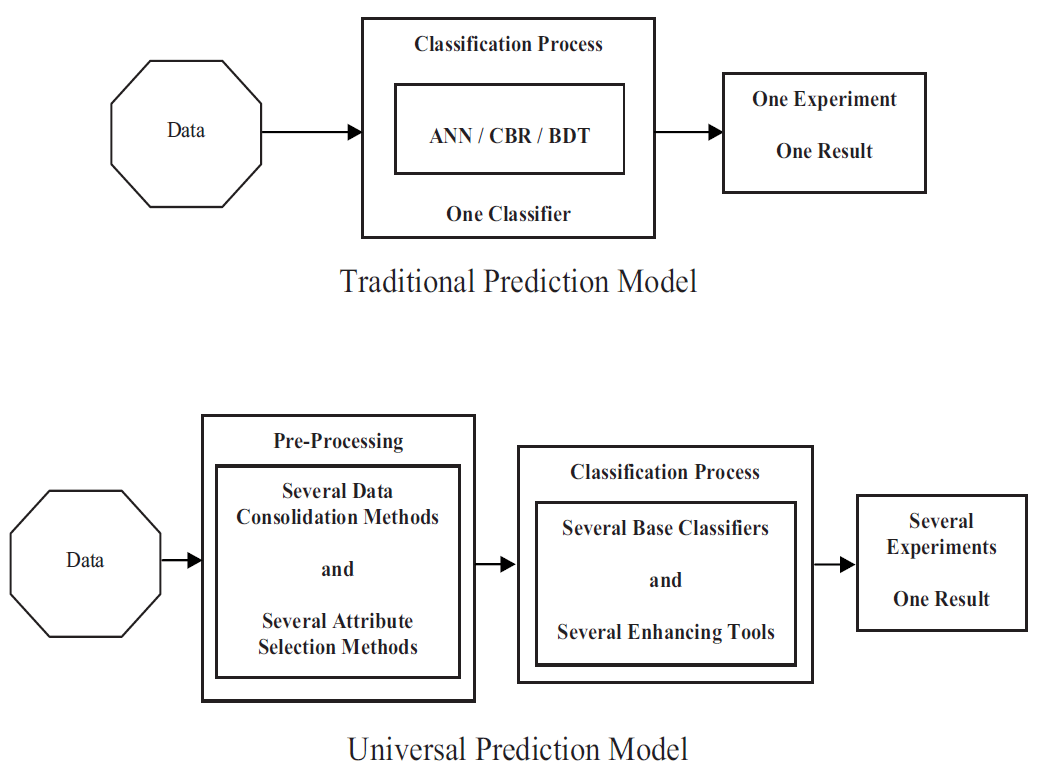
شکل 5. مقایسه مدل پیشبینی سنتی (Traditional Prediction Model) و مدل پیش بینی جهانی (Universal Prediction Model)
ارزیابی نتایج پیشبینی، نسبت بهدقت پیشبینی، پایداری، سرعت محاسبات و تفسیرپذیری رخ میدهد. همچنین آنچه که مدل جهانی پیشبینی (UPM) را نسبت به مدل پیشبینی سنتی متمایز میکند، استفاده از ترکیبی از روشهای متعدد به صورت سازمانیافته، سیستماتیک و خودکار است. این مدل، نتایج بسیاری را در مجموع 3528 در این آزمایش ایجاد میکند که یکی از بهترین آنها انتخاب میشود. مدل جهانی پیشبینی (UPM) در هر چهار دسته عملکرد بسیار خوبی داشته و میتوان ادعا کرد که مدل جهانی پیشبینی (UPM) نهتنها در حوزه دعاوی ساختوساز، بلکه با تغییرات جزئی، برای هر دامنه دیگری نیز قابلاجرا است.
جایگاه مدل پیشبینی جهانی در کشور ایران
باتوجهبه اینکه این مدل در سال 2009 ارائه شده است، ممکن است مدلهای بهینهتری نیز از سوی محققان در سالهای اخیر ارائه شده باشد. همچنین محققان مدیریت پروژه و هوش مصنوعی داخلی میتوانند با انجام مطالعات تکمیلی در این حوزه باتوجهبه پیشرفتهای بزرگی که در حوزه هوش مصنوعی حاصل شده، مدل بهینهتری را ایجاد کرده و ارائه کنند. محققان میتوانند بر اساس رویههای دعاوی در کشورمان ایران مدل فوق را بومیسازی کرده و بهعنوان یک منبع درآمد، کسبوکار جدیدی را تعریف کرده و از آن در جهت حل مشکلات صنعت ساخت استفاده کنند.
همچنین میتوان با ایجاد تغییراتی در ساختار مدل و جمعآوری دادههای موردنیاز در جهت پیشبینی، در بخشهای مختلف دیگری در مدیریت پروژه و ساخت از این مدل استفاده کرد.
- جهت مطالعه بیشتر، فایل مقاله اصلی جهت دانلود قرار داده شده است.
چگونه به متخصص مدیریت ادعا و اختلافات تبدیل شویم؟
در وهله اول توجه داشته باشیم که برای پیادهسازی چنین اصولی نباید از مبانی فنی، قراردادی و حقوقی غافل شد. این الگوریتمها جایگزین تخصص نبوده، بلکه به ما جهت بهینهسازی فرآیندها کمک مینمایند. از اینرو اگر تمایل به یادگیری این اصول دارید، در گام اول باید در این زمینه به یک متخصص ادعا تبدیل شوید. در یکی دیگر از مقالات به توصیف الزامات لازم برای تبدیل شدن به یک متخصص ادعا در کلاس جهانی پرداختهایم.
[1] Arditi, D. Pulket, TH. 2009. Universal Prediction Model for Construction Litigation. JOURNAL OF COMPUTING IN CIVIL ENGINEERING.

